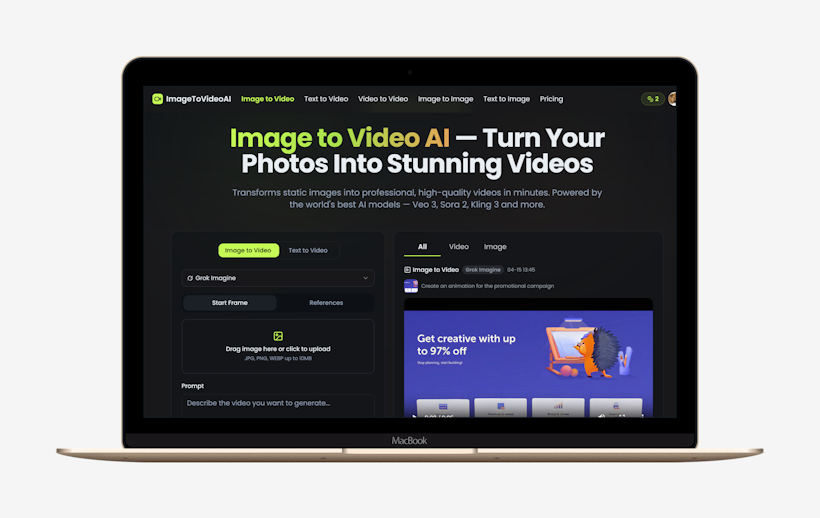
ImageToVideo AI 是什么?
ImageToVideo AI 是一个基于浏览器的在线平台,它集成了 Veo 3、Sora 2、Kling 3 等十余种世界领先的 AI 模型,能够将用户上传的静态图片(JPG, PNG, WebP)通过文字提示词(Prompt)转化为高质量视频。其核心特点是无需下载软件,直接在浏览器中运行,强调快速生成与隐私保护。
ImageToVideo AI 核心功能
- 图生视频 (Image-to-Video)
上传一张图片,配合文字描述(如动作、运镜、氛围),AI 即可生成一段动态视频。支持最长20 秒的视频生成,分辨率最高可达 4K。
- 多模型驱动
平台集成了 10 多种顶级 AI 视频模型(包括 Veo 3, Sora 2, Kling 3 等),用户可根据对画质、真实感或动画风格的不同需求,在平台上切换不同的模型进行生成。
- 精细化 Prompt 控制
用户可以通过文本提示词精确控制视频的各个方面,包括主体运动方式、镜头角度(推拉摇移)、艺术风格和整体情绪,实现“所想即所得”。
- 隐私与安全
官方承诺用户的照片和视频在安全的云端处理,不会被用于 AI 训练,充分尊重用户的数据隐私。
- 全平台适配
生成的视频比例为 9:16(适合 TikTok/Reels)和 16:9,可直接用于社交媒体、广告投放或教学演示。